Hollywood in the CloudBox Office Analytics
A fully automated, cloud-native data engineering project that ingests, processes, and analyzes over 100 years of US Box Office data (1902-2024) using AWS serverless services and Power BI.
Problem & Motivation
The film industry generates massive amounts of box office data spanning over 100 years (1902-2024), but this data exists in fragmented sources. Production studios and film distributors need data-driven insights to answer critical questions: What are long-term trends in movie production? Which genres are most common vs. most popular? How do English and Non-English films compare?
This project builds a production-grade serverless data pipeline on AWS infrastructure that automatically ingests, processes, and analyzes box office data. By implementing a cloud-native architecture with Lambda, S3, Glue, and Athena, this solution enables stakeholders to make strategic decisions about green-lighting projects and optimal release windows.
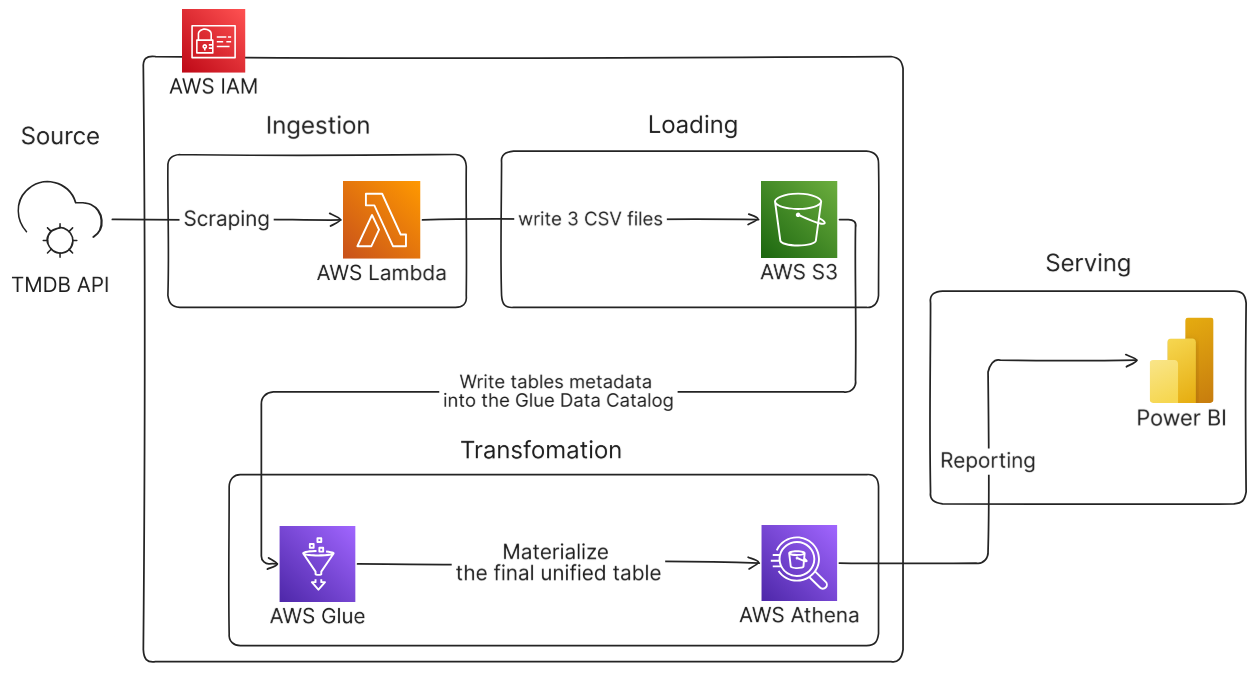
System Architecture
Serverless, event-driven architecture for automated box office analytics
Data Ingestion
AWS Lambda function fetches box office data from TMDB API and stores raw CSV files in S3
Lambda function retrieves top-rated, upcoming movies, and genre data from TMDB API
Raw CSV files stored in S3 with separated locations for crawler compatibility
Schema Discovery
AWS Glue crawlers automatically parse metadata from each CSV file
Crawlers detect schema, data types, and create table definitions in Glue Data Catalog
Individual crawler per CSV file ensures accurate schema parsing for each dataset
Data Transformation
AWS Glue jobs clean and optimize data, then Athena creates unified queryable table
Glue jobs standardize formats, validate data types, and handle missing values
Athena SQL queries combine all sources into single analytical table
Visualization
Power BI connects via ODBC to Athena for interactive dashboard analysis
Secure cloud-to-cloud connection between Power BI and AWS Athena
Real-time analysis of 100+ years of box office trends, genre performance, and language distribution
Pipeline Impact Summary
This serverless pipeline processes over 100 years of box office data (1902-2024), enabling production studios and distributors to make data-driven decisions about genre trends, release windows, and market opportunities.
Pipeline Workflow
Complete end-to-end workflow from API ingestion to interactive dashboards
Data Ingestion
AWS Lambda Function: Automated data fetching from TMDB API (The Movie Database). The function retrieves three datasets: top-rated movies, upcoming movies, and movie genres.
S3 Storage: Raw CSV files stored in S3 Data Lake with separated locations: tmdb/raw/top_rated/, tmdb/raw/upcoming/, tmdb/raw/genres/
Schema Discovery
AWS Glue Crawlers: Automatically parse metadata from each CSV file. Individual crawler per CSV ensures accurate schema detection and data type inference.
Glue Data Catalog: Creates table definitions with proper schemas, enabling SQL-like queries on S3 data without loading into traditional databases.
Data Transformation
AWS Glue Jobs: Clean and optimize data - standardize formats, validate data types, handle missing values, and prepare data for analysis.
AWS Athena: Create unified queryable table combining all three data sources. SQL queries enable complex analytics on box office trends, genre performance, and language distribution.
Visualization
Power BI Connection: Connect to AWS Athena via ODBC driver with AWS credentials and IAM role-based access control.
Interactive Dashboards: Real-time analysis of historical trends (1902-2024), genre performance comparison, language distribution, and seasonal release patterns.
Data Model Architecture
Unified table structure optimized for analytical queries
Unified Movies Table Structure
Top Rated Movies
id, title, release_date, vote_average, popularity
Upcoming Movies
id, title, release_date, vote_average, popularity
Movie Genres
movie_id, genre_name
Unified Table
Combines all sources with language_category (English/Non-English) and genre analysis
The unified table combines top-rated movies, upcoming movies, and genre data into a single analytical structure. Each record includes movie metadata, ratings, popularity scores, genre classification, and language categorization (English vs. Non-English), enabling comprehensive box office trend analysis across 100+ years of film history.
Challenges & Solutions
Key challenges overcome during the development process and their strategic solutions
AWS Lambda Timeout
Problem
Initial function timeout of 3 seconds insufficient for API data fetching
Solution
Extended timeout to 15 minutes and configured environment variables for API authentication
Result
Successfully processes 100+ years of box office data (1902-2024)
S3 Crawler Configuration
Problem
Glue crawler requires separate S3 locations for each dataset to parse metadata correctly
Solution
Split Lambda CSV outputs into dedicated prefixes: tmdb/raw/top_rated/, tmdb/raw/upcoming/, tmdb/raw/genres/
Result
Automatic schema discovery for all three data sources
AWS Glue Schema Parsing
Problem
Multiple data sources with different schemas require individual crawler configuration
Solution
Configured individual crawler per CSV file with custom classifiers for proper type inference
Result
Accurate schema detection and data type mapping across all sources
Power BI Cloud Connectivity
Problem
Connecting Power BI to AWS Athena requires secure cloud-to-cloud integration
Solution
Implemented ODBC service for Athena connection with AWS credentials and IAM role-based access
Result
Real-time interactive dashboards with live data from S3 Data Lake
Business Insights
Discoveries that transformed 100+ years of box office data into strategic business intelligence
Genre Performance
Adventure & Action achieve highest popularity ratings
🎯 High-value genres for production studios
Release Seasonality
Q4 (Oct/Nov) peak for holiday audiences
🎯 Strategic release window planning
Foreign Language Films
French dominates foreign language market
🎯 International distribution insights
Code Showcase
Interactive code browser - click on any file tab to explore the implementation
AWS Lambda - Data Ingestion
import os
import json
import csv
import logging
import urllib.request
import urllib.parse
import boto3
from io import StringIO
# Configure logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# S3 configuration
S3_BUCKET = "tmdb-data-071125"
# Dedicated prefixes for each dataset
TOP_RATED_KEY = "tmdb/raw/top_rated/top_rated_movies.csv"
UPCOMING_KEY = "tmdb/raw/upcoming/upcoming_movies.csv"
GENRES_KEY = "tmdb/raw/genres/movie_genres.csv"
# TMDB configuration
TMDB_BASE_URL = "https://api.themoviedb.org/3"
TMDB_API_TOKEN = os.getenv("TMDB_API_TOKEN")
# AWS client
s3_client = boto3.client("s3")
def _make_tmdb_request(endpoint: str, params: dict | None = None) -> dict:
"""Perform a GET request to TMDB using urllib with Bearer token auth."""
if not TMDB_API_TOKEN:
logger.error("TMDB_API_TOKEN environment variable is not set")
raise RuntimeError("TMDB_API_TOKEN environment variable is required")
if params is None:
params = {}
query = urllib.parse.urlencode(params)
url = f"{TMDB_BASE_URL}{endpoint}"
if query:
url = f"{url}?{query}"
logger.info(f"Requesting TMDB URL: {url}")
headers = {
"Authorization": f"Bearer {TMDB_API_TOKEN}",
"Accept": "application/json"
}
request = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(request) as response:
return json.loads(response.read().decode())
def lambda_handler(event, context):
"""Main Lambda handler to fetch and store TMDB data"""
try:
# Fetch top rated movies
top_rated = _make_tmdb_request("/movie/top_rated", {"page": 1})
# Process and upload to S3...
return {
'statusCode': 200,
'body': json.dumps('Data ingestion completed successfully')
}
except Exception as e:
logger.error(f"Error: {str(e)}")
raiseKey Learnings & Future Vision
Key learnings from implementation and strategic vision for evolving capabilities
💡 Key Learnings
Serverless Architecture Design
Learned to design fully serverless, event-driven pipelines that scale automatically and minimize infrastructure costs
AWS Service Integration
Mastered integration patterns between Lambda, S3, Glue, Athena, and Power BI for seamless data flow
Data Lake Best Practices
Understood proper S3 organization, crawler configuration, and schema evolution patterns for data lakes
Cloud Security & IAM
Gained expertise in IAM role-based access control and least privilege permissions for cloud services
🚀 Future Enhancements
Real-time Streaming
Add Kinesis Data Streams for real-time movie release and box office updates
Machine Learning Integration
Build predictive models for box office performance using historical trends and genre patterns
Multi-source Integration
Extend pipeline to include additional data sources like Rotten Tomatoes, IMDb ratings
Advanced Analytics
Implement time-series analysis for long-term industry trends and forecasting
"Serverless data engineering is about building systems that scale automatically, cost-effectively, and reliably—transforming raw data into insights without managing infrastructure."
"تَعَبُ كُلّها الحَياةُ."
© 2025 Yousef Mahmoud | Data Engineering Portfolio